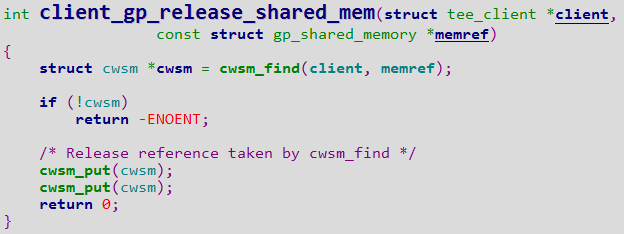
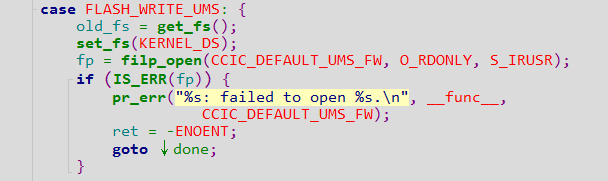
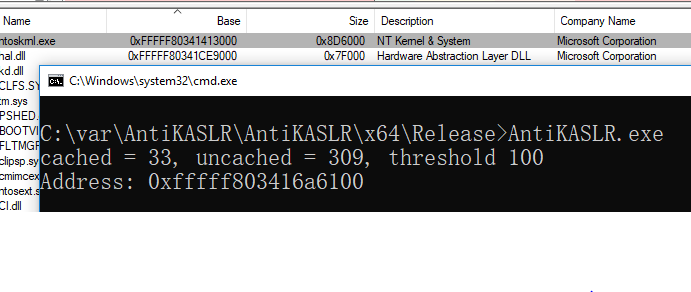
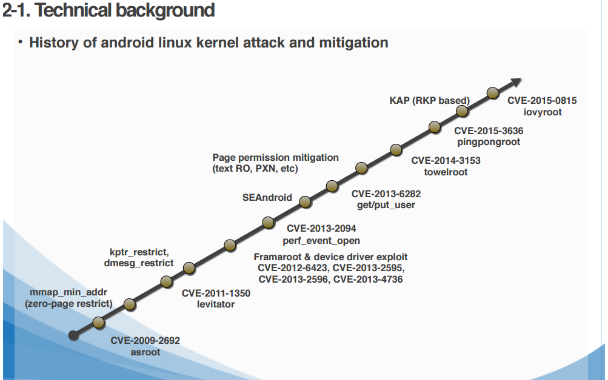
对照qemu的源码可知,qemu为aarch64模拟器环境提供了串口设备PL011。我们研究了Linaro UEFI的源码EDK2并编译了对应的UEFI文件,确保使用的UEFI文件确实提供了串口功能。再用与Win10ARM64模拟器同样的配置安装了Ubuntu for ARM,在这个模拟器里PL011串口通信正常,串口采用MMIO,其映射的基址为0x09000000。但安装Win10后问题依旧:以基于串口的远程内核调试的启动配置来启动Win10RS4ARM64,系统加载的是kd.dll而非期望的kdcom.dll,故而推测是winload 没有识别PL011串口设备、没能去加载kdcom.dll。由此,我们决定直接将kdcom.dll替换kd.dll来使用。不过使用kdcom.dll替换kd.dll后出现了新的问题——系统引导异常,下面进一步分析其原因。
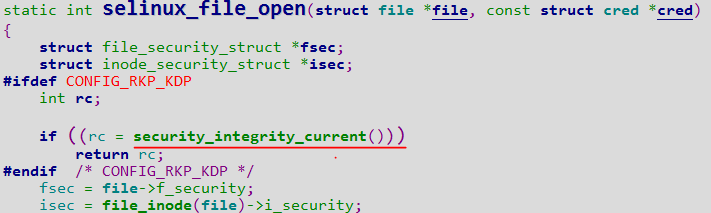
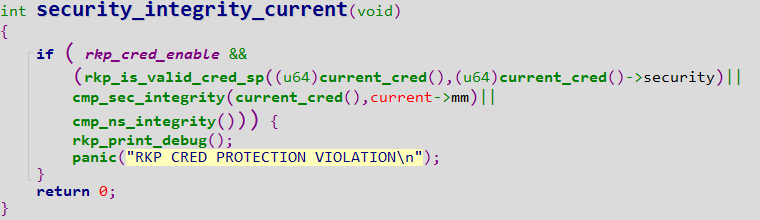
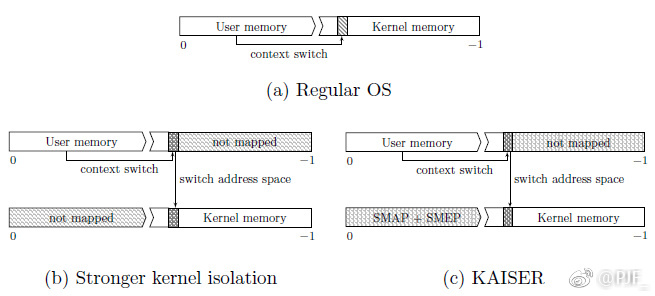
之前短文提到了操作系统抵御meltdown的方案是用户态使用另一份不映射内核绝大多数地址空间的页表(Windows上的KVA Shadowing和Linux上的KPTI,它们源自KAISER),那么已有方案是否完美呢?答案是否定的,下面以微软补丁方案为例介绍一个导致全补丁下KASLR Bypass的简单缺陷。(注意虽说原理极为简单,但为了确认是否能公开,两周前已将缺陷报给了MSRC,刚得到微软确定答复。小小吐槽一下,微软认为其威胁不大、不归于漏洞这点在意料之中,但给的理由又是常用的一个:“This is by design”,给人的感觉就是专门留下这点设计来废掉KASLR,其实KAISER原本就是设计用于防止针对KASLR的边信道攻击,本质上还是算方案设计有遗漏)
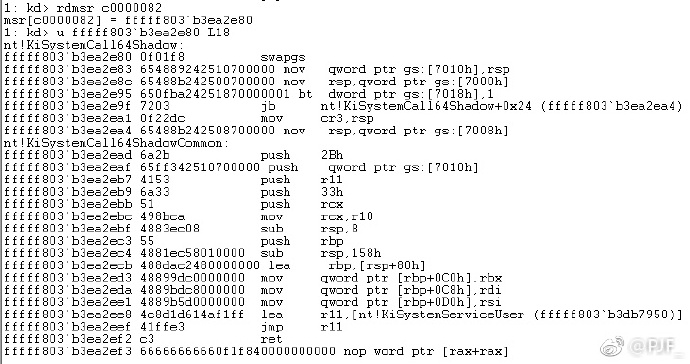
那么微软为什么要在RS4引入Dual-CR3,这要从内核地址空间随机化(KASLR)说起了,Win10 KASLR随机化了模块的加载基址、内核对象地址、页表地址等,缓解了内核漏洞的利用。不过之前微软对各种基于硬件的边信道攻击(double page fault、prefetch side-channel、TSX-based side-channel等等)依然是没有防护的,这次引入Dual-CR3至少目标中包含增加该种防护。学术圈对该类攻击和防御手段研究已经多时了,今年《KASLR is Dead: Long Live KASLR》这篇论文为Linux设计实现的内核地址隔离方案KAISER号称性能损失仅有0.28%,当初看到的时候只凭感觉每次系统调用都切换CR3、把非Global的TLB项清除(何况为了实现内核地址强隔离应该是没有Global项),这性能损失怎么会这么小(论文里倒是提供了一下解释:首先Global没什么用”Surprisingly, we found the performance impact of disabling global bits to be entirely negligible”;其次现代CPU对TLB管理的优化使得频繁切CR3也没什么大损失了)。没想到没几个月微软就直接在Win10上完全照搬了这套方案(不是每个进程都切换)。这套方案原理简单可行,参见附图一(论文附图)就一目了然了。微软在进程—_KPROCESS中增加了UserDirectoryTableBase配合原有DirectoryTableBase即提供论文中描述的CR3 Pair的内容。线程运行时,_KPRCB中的KernelDirectoryTableBase、RspBaseShadow、UserRspShadow、ShadowFlags用于模式转换时的隔离切换,需要加入的代码很少,附图二是Intel CPU的系统调用入口的代码,返回时自然也有相应的处理。
/* This is passed in from userspace into the kernel keyring */ structext4_encryption_key { __u32 mode; char raw[EXT4_MAX_KEY_SIZE]; __u32 size; } __attribute__((__packed__));
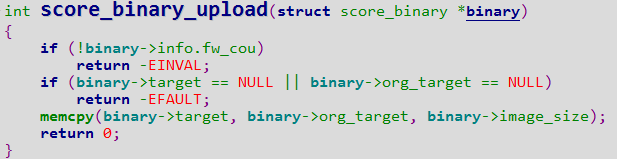
//若ext4_inode_info中的i_crypt_info有值,说明先前已经初始化好 if (ei->i_crypt_info) return0; if (!ext4_read_workqueue) { /*为readpage时解密初始化read_workqueue,为ext4_crypto_ctx预先创建128个 *cache,为writepage时用的bounce page创建内存池,为ext4_crypt_info创建slab */ res = ext4_init_crypto(); if (res) return res; }
/*从xattr中读取加密模式、master key descriptor、nonce等加密相关信息到 *ext4_encryption_context */ res = ext4_xattr_get(inode, EXT4_XATTR_INDEX_ENCRYPTION, EXT4_XATTR_NAME_ENCRYPTION_CONTEXT, &ctx, sizeof(ctx)); if (res < 0) { if (!DUMMY_ENCRYPTION_ENABLED(sbi)) return res; ctx.contents_encryption_mode = EXT4_ENCRYPTION_MODE_AES_256_XTS; ctx.filenames_encryption_mode = EXT4_ENCRYPTION_MODE_AES_256_CTS; ctx.flags = 0; } elseif (res != sizeof(ctx)) return -EINVAL; res = 0;
crypt_info = kmem_cache_alloc(ext4_crypt_info_cachep, GFP_KERNEL); if (!crypt_info) return -ENOMEM;
/* dentry private data. Each dentry must keep track of a lower vfsmount too. */ structecryptfs_dentry_info { structpathlower_path; union { structecryptfs_crypt_stat *crypt_stat; structrcu_headrcu; }; };
Discovering vulnerabilities in operating system (OS) kernels and patching them is crucial for OS security. However, there is a lack of effective kernel vulnerability detection tools, especially for closed-source OSes such as Microsoft Windows. In this paper, we present Digtool, an effective, binary-code-only, kernel vulnerability detection framework. Built atop a virtualization monitor we designed, Digtool successfully captures various dynamic behaviors of kernel execution, such as kernel object allocation, kernel memory access, thread scheduling, and function invoking. With these behaviors, Digtool has identified 45 zero-day vulnerabilities such as out-of-bounds access, use-after-free, and time-of-check-to-time- of-use among both kernel code and device drivers of recent versions of MicrosoftWindows, includingWindows 7 and Windows 10.
QCEDEV_IOCTL_SHA_INIT_REQ is for initializing a hash/hmac request. QCEDEV_IOCTL_SHA_UPDATE_REQ is for updating hash/hmac. QCEDEV_IOCTL_SHA_FINAL_REQ is for ending the hash/mac request. QCEDEV_IOCTL_GET_SHA_REQ is for retrieving the hash/hmac for data packet of known size. QCEDEV_IOCTL_GET_CMAC_REQ is for retrieving the MAC (using AES CMAC algorithm) for data packet of known size.
The caller of the IOCTL passes a pointer to the structure shown below, as the second parameter.
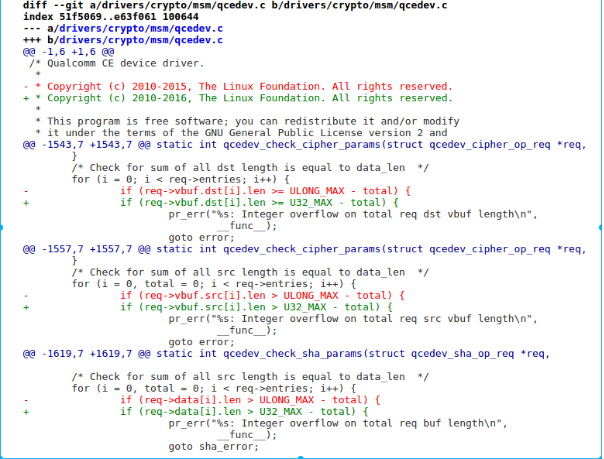
/* Check for sum of all src length is equal to data_len */ for (i = 0, total = 0; i < req->entries; i++) { if (req->data[i].len > ULONG_MAX - total) { pr_err("%s: Integer overflow on total req buf length\n", __func__); goto sha_error; } total += req->data[i].len; }
/* Maximum value an `unsigned long int' can hold. (Minimum is 0.) */ # if __WORDSIZE == 64 # define ULONG_MAX 18446744073709551615UL # else # define ULONG_MAX 4294967295UL # endif
Split thread_info off of kernel stack (Done: x86, arm64, s390. Needed on arm, powerpc and others?) * Move kernel stack to vmap area (Done: x86, s390. Needed on arm, arm64, powerpc and others?)
Implement kernel relocation and KASLR for ARM
Write a plugin to clear struct padding
Write a plugin to do format string warnings correctly (gcc’s -Wformat-security is bad about const strings)
Make CONFIG_STRICT_KERNEL_RWX and CONFIG_STRICT_MODULE_RWX mandatory (done for arm64 and x86, other archs still need it)
Convert remaining BPF JITs to eBPF JIT (with blinding) (In progress: arm)
Write lib/test_bpf.c tests for eBPF constant blinding
Further restriction of perf_event_open (e.g. perf_event_paranoid=3)
Extend HARDENED_USERCOPY to use slab whitelisting (in progress)
Extend HARDENED_USERCOPY to split user-facing malloc()s and in-kernel malloc()svmalloc stack guard pages (in progress)
protect ARM vector table as fixed-location kernel target
disable kuser helpers on arm
rename CONFIG_DEBUG_LIST better and default=y
add WARN path for page-spanning usercopy checks (instead of the separate CONFIG)
create UNEXPECTED(), like BUG() but without the lock-busting, etc
Sometimes an attacker won’t be able to control the instruction pointer directly, but they will be able to redirect the dereference a structure or other pointer. In these cases, it is easiest to aim at malicious structures that have been built in userspace to perform the exploitation.
This Patch-Tuesday MS fixed 6 kernel information leak vulnerabilities reported by us, the details are at the end of this article. I had already show how to fuzz the windows kernel via JS , today we will introduce a new method to discover windows kernel vulnerabilities automatically without fuzzing. I selected a small part from the work in the past few months to spread out this topic.
KASLR
In Windows Vista and above, Microsoft enable Kernel Address Space Layout Randomization (KASLR) by default to prevent exploitation by placing various objects at random addresses, rather than fixed ones. It is an effective method against exploitation using Return-oriented Programming (ROP) attack.
Beginning with Windows 8, KASLR is enhanced with a newly introduced function ExIsRestrictedCaller. Programs under medium integrity are not able to invoke functions such as NtQuerySystemInformation to obtain addresses of kernel modules, kernel objects or pools.
The above is the traditional way to get the kernel module address and kernel object address, as the kernel normal feature. But after win8, low integrity application will fail in calling these functions.
In order to bypass KASLR, a direct countermeasure is to discover vulnerabilities that leak valuable information from the kernel mode to calculate the address of kernel module or kernel object.
Kernel Information Leak
As a kind of kernel vulnerability, it has its own uniqueness. For example, for the traditional memory damage vulnerabilities, the vulnerability itself will affect the running of the kernel. With the help of verifier and other tools, you can easily capture this exception among the normal traffic. But the kernel information leak vulnerability does not trigger any exception, nor does it affect the running of the kernel, which makes it more difficult to be discovered. Vulnerabilities objectively exist, what we need to do is to find them at lowest cost.
Discover ideas
When kernel information leak vulnerability occurs, the kernel will certainly write some valuable data to the user buffer. So if we monitor all the writing behaviors to user buffer in the kernel, we will be able to find them.
Of course, the system does not provide this feature. I capture the process with the help of a hardware virtualization based framework of pjf, who is the author of the famous windows kernel anti-rootkit tool named iceSword.
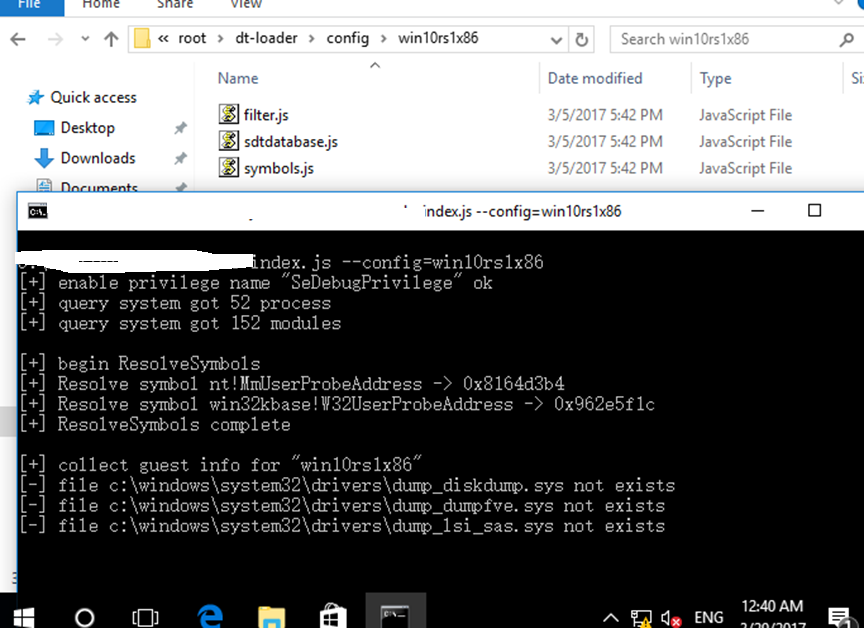
In order not to affect the dest system itself, I monitored in the VMWARE guest and write some log files, and then further analyze them in the host system.
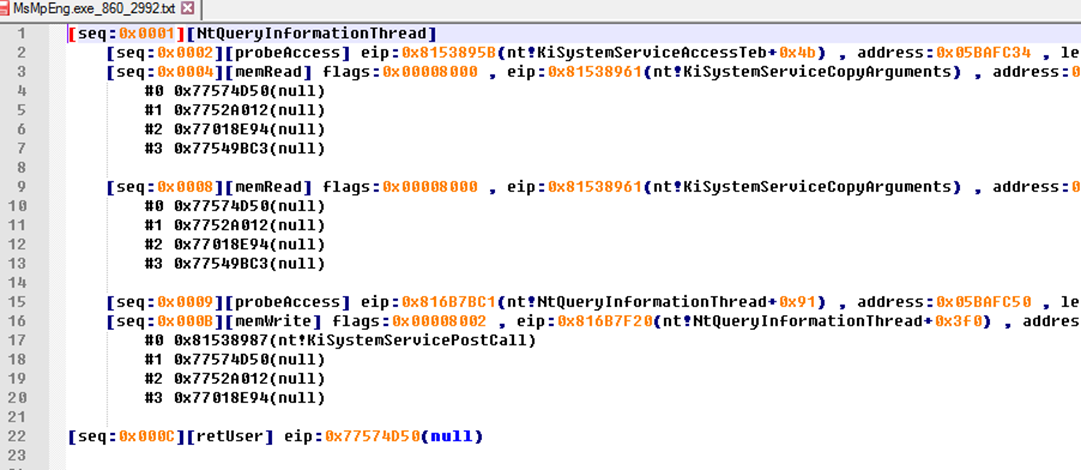
In the host machine, after decoding and analyzing the logs:
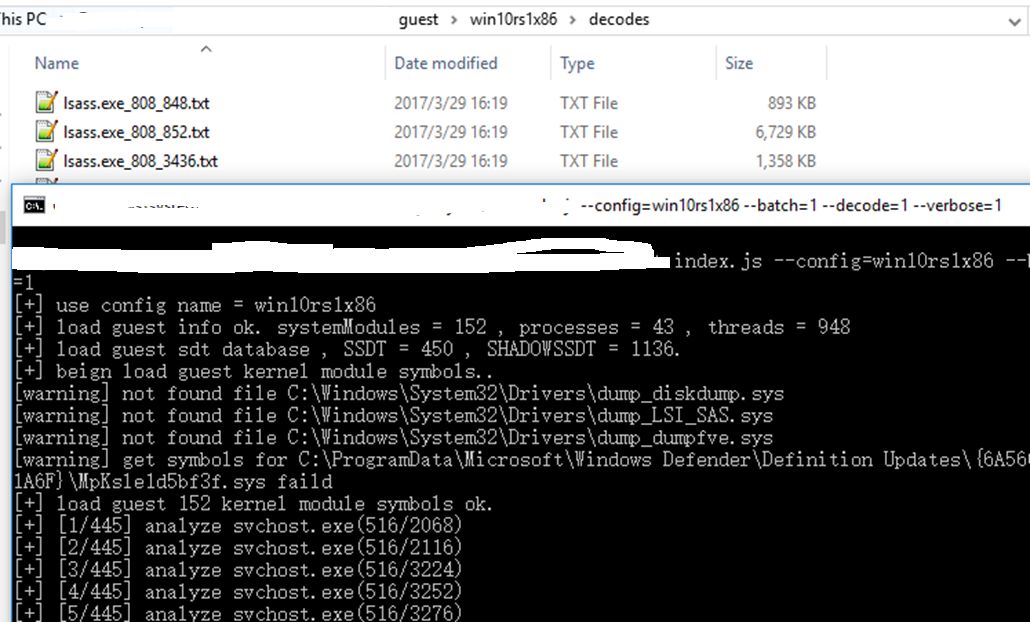
Then we have the human-readable logs:
Further Analysis
Now we have operation records in user memory buffer written by kernel. Most of them are just normal functions.
We need remove nosiy data to find out the key information. Two skills are needed.
Poison the kernel stack
Poisoning or polluting the target is a common idea. At network penetration testing, there are also ARP and DNS cache poisoning.
Here is the kernel stack poisoning, refers to the pollution to the entire unused kernel stack space.
If a variable on a kernel stack is not initialized, then when this variable is written to the user buffer, there will be a magic value in the record written by me. Wherever these is a magic value, there is a leak.
I noticed that j00ru also used similar techniques in his BochsPwn project.
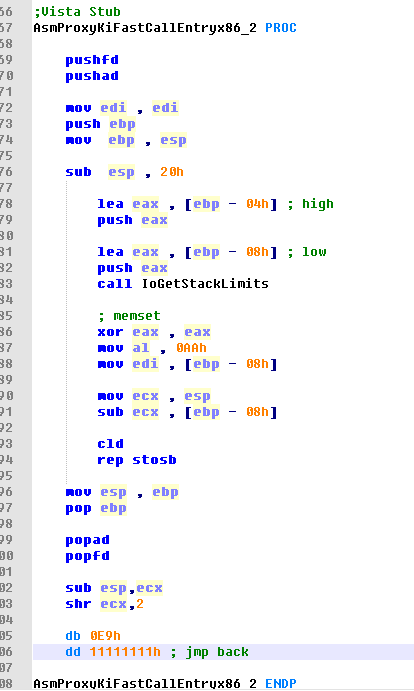
KiFastCallEntry Hook
In order to poison the kernel stack, I hooked nt!KiFastCallEntry. So that when a syscall invoked, I can poisoning the entire unused kernel stack space.
Firstly, I used ** IoGetStackLimits ** to get the current thread stack range, and then from the bottom of the stack to the current stack location of the entire space are filled with 0xAA.
So when I entered the syscall, all the contents of the local variables on the kernel stack will be filled into 0xAA.
Poison the kernel pool
Similarly, for dynamically allocated memory, I used hook nt!ExAllocatePoolWithTag and so on, and polluted its POOL content.
If the kernel stack/heap variable is not properly initialized, it is possible to write this magic value to the user buffer.
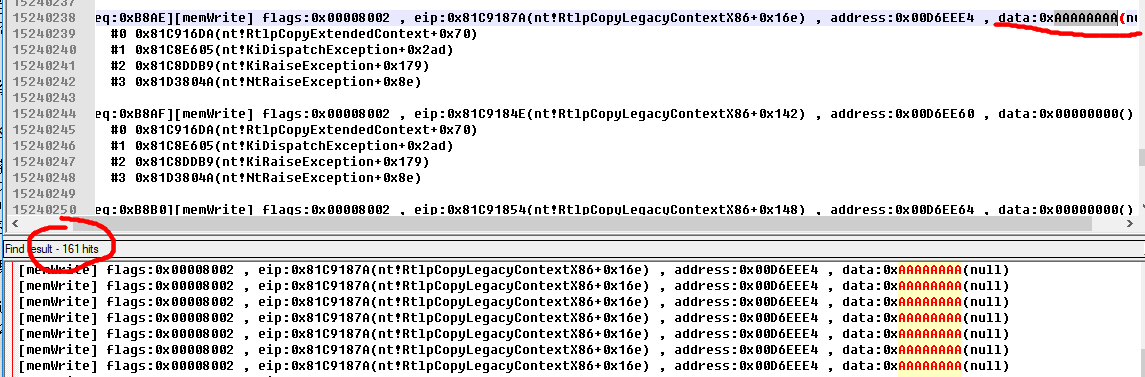
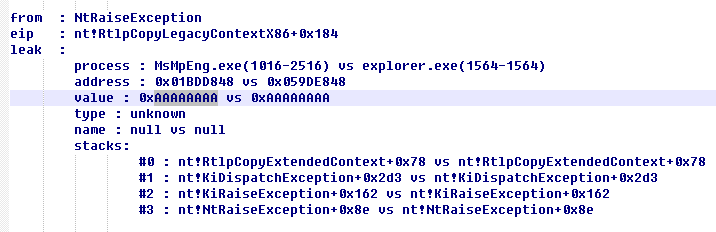
With the help of the logs we captured, we can immediately find this vulnerability. In order to remove the coincidence, I also used a number of magic value such as 0xAAAAAAAA , 0xBBBBBBB to exclude false positives.
A typical result after excluding the interference is as follows.
You can see that in a short monitoring process, it caught the ** 161 ** leaks in the system! Of course, this is not exhaustive. There are not so many independent vulnerabilities, but some vulnerabilities made repeated leaks.
At this point we caught a real information leak vulnerability, there is stack information, supplemented by a simple manual analysis, we can got the details. This is also the story behind the CVE-2017-8482.
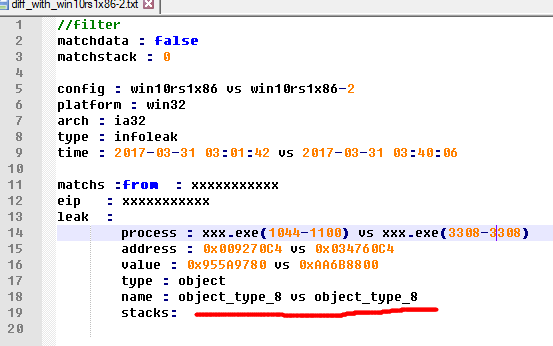
Difference comparison
For the kernel information leak caused by the uninitialized stack, we can poison them at first and then find them. But for the direct disclosure of key information, such as the module and the object address written directly, it cannot be found in this way.
In the process of the system running, the kernel itself will frequently write data to the user buffer, a lot of data is in the kernel address range, but in fact it is not a valid address, but a noise data. There are many such noise data, such as strings, pixels, rect, region, etc. which are likely happen to be a kernel address. We need to rule out the noise and found a real leak.
Here we filter out some meaningful addresses, such as:
Module address, must be inside in the system module list
object address
POOL address
After the environment changes, such as restarting the system, it must be able to leak the same type of data at the same location.
After the exclusion of the normal function of the system, such as NtQuerySystemInformation and similar functions, the left data’s credibility is very high.
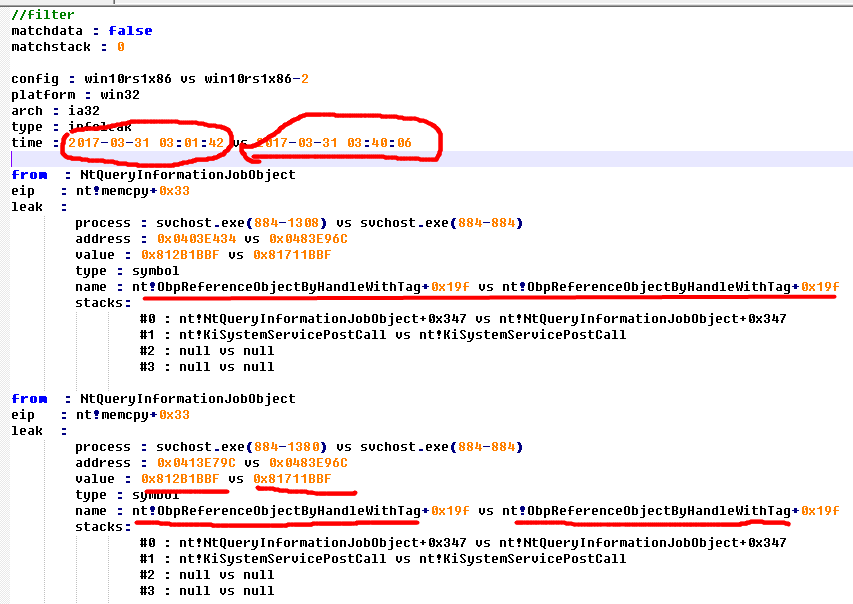
The leak of module address
For example CVE-2017-8485
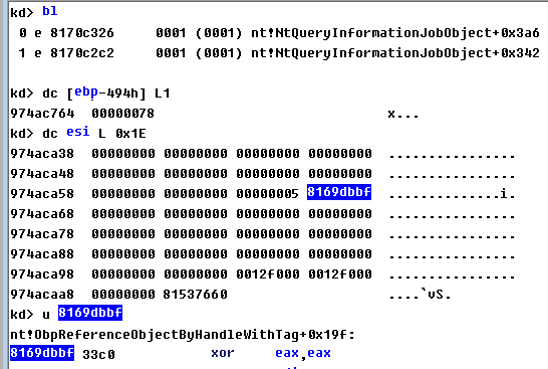
You can see that the results at this time is very obvious - the same stack, the same location, are leaked nt! ObpReferenceObjectByHandleWithTag + 0x19f
The leak of object address
Due to leakage of object address and POOL address not fixed by Microsoft this month, I cannot describe the details.
More
You can see that we do not need a fuzzer, only through the code coverage generated by normal running of the system itself, we found these vulnerabilities. Any normal program running can improve this coverage. In fact, in the actual work, I only use the game and the browser to improve coverage and got good results. A game finished, ten kernel vulnerabilities on the hand.